|
A New View of Statistics | |
![]() ON
THE FLY FOR DIFFERENCES BETWEEN MEANS
ON
THE FLY FOR DIFFERENCES BETWEEN MEANS
A variant of the method also works for longitudinal studies--for
example, where you want to compare the strength of females before and
after they take a hormone that makes them like males. We'll come to
those in a minute.
![]() Cross-Sectional Studies
Cross-Sectional Studies
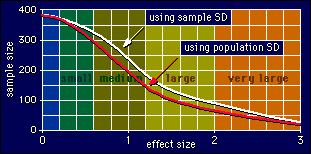
Recall that the effect size is the difference between the means divided by the average standard deviation of the two groups. Well, the standard deviation calculated from your sample introduces some error of its own, which contributes to error in the effect size. So if you have a more accurate estimate of the population standard deviation from elsewhere, use it instead of the value from your sample. It can mean 40 less subjects, depending on how big the effect is. It also makes calculating the confidence limits of the effect size a lot easier.
Here's the method, for either standard deviation.
|
|
|
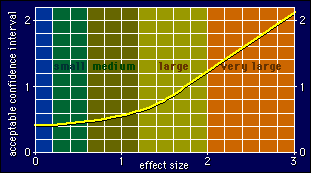
Cool! You've got a value for the effect size, and you've done it
with the minimum number of subjects, and it's practically unbiased by
doing it on the fly, and you know that its confidence interval is
narrow enough that it can't overlap more than two steps (colors) on
the qualitative magnitude scale. But what exactly is the value
of the confidence interval? If I end up refereeing your paper, I'll
insist you put it in! Here's how to get it.
Confidence Limits for Effect
Size (Cross-sectional Studies)
If you used the population standard deviation for
sample sizing on the fly, get your stats program to produce the
confidence interval of the raw difference between the means for the
final sample. Divide this confidence interval by the population
standard deviation and you have the exact confidence interval for the
effect size. The observed effect size sits symmetrically in the
middle of this confidence interval. If you can't get your stats
program to produce the confidence interval of the difference score,
the confidence interval of the effect size is given exactly by
2t·sqrt(4/N), where N is the total sample size, and t is the
value of the t statistic for N - 2 degrees of freedom and
cumulative probability 0.975. The value of t is near enough to 2.0.
If you used the sample standard deviation on the fly, the resulting
effect size is biased a bit high for small total sample sizes (N). Adjust out
the bias using this formula:
unbiased ES = (observed
ES)(1 - 3/(4N - 1)).
Now use the following fairly accurate formula to calculate the 95% confidence
interval for the unbiased effect size:
95% confidence interval = 4sqrt(4/N + ES2/(N - 2)).
The confidence limits are therefore given fairly accurately by:
ES ± 2sqrt(4/N + ES2/(N - 2)),
but that's only for ES<1.0. For larger values of ES, the limits start to
sit asymmetrically about the observed value of ES. Then the going gets really
tough. The exact values of the confidence limits are given by t·sqrt(4/N),
where t is the value of the non-central t statistic with degrees of freedom = N - 2,
non-central parameter = ES·sqrt(N/4), and cumulative probabilities
of 0.025 and 0.975 for the lower and upper limits respectively. Only advanced
stats programs can produce values for the non-central t statistic.
All the above formulae are available on the spreadsheet, with the exception of the non-central t statistic. I will add it when Excel does.
Reference for formulae:
Becker, B. J. (1988). Synthesizing standardized mean-change measures.
British Journal of Mathematical and Statistical Psychology, 41,
257-278.
![]() Longitudinal Studies
Longitudinal Studies
But if we use the sample standard deviation to calculate the effect size, there is a major hitch. With the small sample sizes that are possible, the error in the standard deviation is proportionally larger, so the confidence interval of the effect size ends up large after all, so we lose the benefit of the high reliability and end up with larger sample sizes again. The calculations are difficult, too.
On the other hand, if we know or can guess the population standard
deviation, all is saved. So I'll concentrate on a method that uses
the population standard deviation, then deal briefly with the use of
the sample standard deviation.
Using Population SD to Calculate Effect Size and its Confidence
Limits
This method works for the effect size in cross-sectional or
longitudinal designs of any kind, and for any
estimates/contrasts between
levels of within and between factors. Wow! The only challenge for you
is to coax your stats program to produce a confidence interval for
the raw difference between the means, or for whatever
estimate/contrast you are interested in. You then simply convert that
to a confidence interval for the effect size by dividing it by the
population standard deviation, see if the confidence interval is
narrow enough, and if it's not, work out how many more subjects
you'll need.
This paragraph may confuse you. Skip to the method in the next paragraph if it does. To get an idea of the kind of sample sizes you can end up with, you can apply the formulae I presented earlier for the effects of reliability on sample size. The only difference is, the "N" in the formulae is now the sample size you would need for a cross-sectional study, as shown by the curve in the above graph for population SD. So, the sample size for a longitudinal study with a single pre and post measurement and no control group is N(1 - r)/2, where r is the reliability correlation coefficient. If there is a control group, you need twice as many in both groups, or 2N(1 - r) altogether. Let's check out an example on the graph above. If your effect size turns out to be in the middle of the medium range, you'd end up needing about 200 subjects for a cross-sectional study. But if your reliability is 0.9, that'll come down to 10 subjects for a study without a control group! Fantastic! If your reliability is 0.95--not out of the question for some outcome measures--you'd need only 10 subjects in each group of a properly controlled study. It will be even less for larger effects. But check the graph: you might still have to go to nearly double that number if the effect size turns out to be zero.
OK, here's how the method works. It's the usual iterative process, but this time it relies on the fact that the width of the confidence interval is inversely proportional to the square root of the sample size.
|
|
|
The confidence interval of the final effect size is no problem,
this time. You've been calculating it all along.
Using Sample
SD to Calculate Effect Size and its Confidence Limits
You go through the same steps as for use of the population SD,
but you have to calculate the confidence interval for the effect size
using the sample SD. You then use this calculated confidence interval
in Step 3. Here's how to calculate the confidence interval. If you
have a control group, I will assume it has the same number of
subjects as the experimental group.
When you've done your sampling on the fly, the confidence limits of the effect size, for effect sizes <1, are given by the final effect size ± half the confidence interval. For effect sizes>1 there is that problem of the confidence interval not sitting symmetrically around the effect size...
For studies without a control group, the exact values of the confidence limits are given by t·sqrt(4(1 - r)/N), where t is the value of the non-central t statistic with degrees of freedom = N - 2, non-central parameter = ES·sqrt(N/(4(1 - r)), and cumulative probabilities of 0.025 and 0.975 for the lower and upper limits respectively.
For studies with a control group, the exact values of the confidence limits are given by t·sqrt(8(1 - r)/N), where t is the value of the non-central t statistic with degrees of freedom = N - 2, non-central parameter = ES·sqrt(N/(8(1 - r)), and cumulative probabilities of 0.025 and 0.975 for the lower and upper limits respectively.
If only the stats programs would do these calculations...! I've put most of them on the spreadsheet, but I can't do anything about non-central t statistics until Excel does.
If you've got this far, you will no doubt be interested in a simulation that validates the on-the-fly method for the case of no control group. It includes an empirical check on the formulae when there is a control group.
Now for something a little easier: on the
fly for differences in frequencies.
Go to: Next · Previous · Contents · Search
· Home
resources=AT=sportsci.org · webmaster=AT=sportsci.org · Sportsci Homepage · Copyright
©1997
Last updated 13 June 97