|
A New View of Statistics | |
![]() T Test and One-Way ANOVA
T Test and One-Way ANOVA
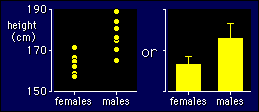 In other
words, if you know someone's sex, what does that tell you about their height?
Or, how well do the height data fall into two groups when you label the values
by sex? The test statistic for the test of whether sex has an effect on height
is called Student's t, or just t. Hence the name of this model, the t test.
In other
words, if you know someone's sex, what does that tell you about their height?
Or, how well do the height data fall into two groups when you label the values
by sex? The test statistic for the test of whether sex has an effect on height
is called Student's t, or just t. Hence the name of this model, the t test.
When there are three or more levels for the nominal variable, a simple approach is to run a series of t tests between all the pairs of levels. For example, we might be interested in the heights of athletes in three sports, so we could run t test for each pair of sports. (Note that this approach is not the same as a paired t test. That comes later.) A more powerful approach is to analyze all the data in one go. The model is the same, but it is now called a one-way analysis of variance (ANOVA), and the test statistic is the F ratio. So t tests are just a special case of ANOVA: if you analyze the means of two groups by ANOVA, you get the same results as doing it with a t test.
The term analysis of variance is a source of confusion for newbies. In spite of its name, ANOVA is concerned with differences between means of groups, not differences between variances. The name analysis of variance comes from the way the procedure uses variances to decide whether the means are different. A better acronym for this model would be ANOVASMAD (analysis of variance to see if means are different)! The way it works is simple: the program looks to see what the variation (variance) is within the groups, then works out how that variation would translate into variation (i.e. differences) between the groups, taking into account how many subjects there are in the groups. If the observed differences are a lot bigger than what you'd expect by chance, you have statistical significance. In our example, there are only two groups, so variation between groups is just the difference between the means.
I won't bother with trying to represent this model as an equation like Y = mX + c. Suffice to say that it can be done, simply by making an X variable representing sex that has the value 0 for females and 1 for males, say (or vice versa). So it is also a "linear" model, even though we don't normally think about it as a straight line. The parameters in the model are simply the mean for the females and the mean for the males.
The spreadsheet for analysis of controlled
trials includes a comparison of the means (and standard deviations) of two
groups at baseline. You can use it for any tests of two independent groups,
as in the above example.. Ignore all the stuff related to comparisons of changes
in the mean in the two groups.
Comparisons of Means
With a t test,
the thing we're most interested in is, of course, a comparison of the two means.
You should think about the best way to express the difference
in the means for your data: raw units, percent difference, or effect size.
And don't forget to look at and discuss the magnitude of the difference and
the magnitude of its confidence limits.
With three or more levels for the nominal variable, we can start asking interesting
questions about the differences between pairs or combinations of means. Such
comparisons of means are known as estimates or contrasts.  For example, suppose we are exploring the relationship
between training hours per week (the dependent variable) and sport (the nominal
independent variable). Suppose sport has three levels: runners, cyclists, and
swimmers, as shown. We can ask the question, are there differences overall between
the sports? The answer would be given by the p value for sport in the model.
And what about the difference between cycling and running? Yes, we can dial
up the difference and look at its p value or confidence interval. We do that
by subtracting the value for the parameter (the mean) for cycling from that
for running, using the appropriate syntax in the stats program. We could even
ask how different swimming was from the average of running and cycling, and
so on. There's also a special kind of contrast (polynomials)
you can apply if the levels are a numbered sequence and you want to describe
a curve drawn through the values for each level.
For example, suppose we are exploring the relationship
between training hours per week (the dependent variable) and sport (the nominal
independent variable). Suppose sport has three levels: runners, cyclists, and
swimmers, as shown. We can ask the question, are there differences overall between
the sports? The answer would be given by the p value for sport in the model.
And what about the difference between cycling and running? Yes, we can dial
up the difference and look at its p value or confidence interval. We do that
by subtracting the value for the parameter (the mean) for cycling from that
for running, using the appropriate syntax in the stats program. We could even
ask how different swimming was from the average of running and cycling, and
so on. There's also a special kind of contrast (polynomials)
you can apply if the levels are a numbered sequence and you want to describe
a curve drawn through the values for each level.
If you're expressing a difference between means as an effect size, the standard deviation to use in the calculation is the root mean square error (RMSE) in the ANOVA. An ANOVA is based on the assumption that the standard deviation in the same in all the groups, and the RMSE represents the estimate of that standard deviation. You can think of the RMSE as the average standard deviation for all of the groups.
With lots of contrasts, the chance of any one of them being spuriously statistically significant--in other words, the overall chance of a Type I error--goes up. So stats programs usually have built-in ways of controlling the overall Type I error rate in an ANOVA. Basically they adjust the p value down for declaring statistical significance, although you don't see it like that on the printout. These methods have statisticians' names: Tukey, Duncan, Bonferroni... They're also known as post-hoc tests or simply post hocs. I don't use them, because I now use confidence limits and clinical significance rather than statistical significance, so I don't test anything.
One approach to controlling the Type I error rate with multiple contrasts is
simply not to perform the contrasts unless the overall effect is significant.
In other words, you don't ask where the differences are between groups
unless there is an overall difference between groups. Sounds reasonable,
but wait a moment! If there is no overall statistically significant difference
between groups, surely none of the contrasts will turn up significant? Yes,
it can happen! There's jitter in the p values, and there's nothing to say that
the p value for the overall effect is any more valid than the p value for individual
contrasts. So if you've set up your study with a particular contrast in mind--a
pre-planned contrast--go ahead and do that
contrast, regardless of the p value for the overall effect. Performing the pre-planned
contrast does not have to be contingent upon obtaining significance for the
overall effect. Those of us who prefer confidence intervals to p values can
understand why: the estimate of the difference between groups has a confidence
interval that may or may not overlap zero, and the confidence interval for the
overall effect (expressed in some measure of goodness of fit) may or may not
overlap zero. There is no need to reconcile the two.
Goodness of Fit
What statistic
do we use to talk about how well the ANOVA model fits the data? It's not used
that frequently, but you can extract an R2
just like you do for a straight line. The R2
represents how well all the levels of the grouping (nominal) variable fit the
data. More about goodness of fit soon.
Go to: Next · Previous · Contents · Search
· Home
editor
Last updated 2 Nov 03